Week 1: How to Win a Data Science Competition - HWDSC
Contents
“How to Win a Data Science Competition: Learn from Top Kagglers” by National Research University Higher School of Economics 课程笔记。
1. Competition Mechanics
Competition’s Concepts
- Data
- Model
- Submission
- Evaluation
- Leaderboard
Evaluation
- Accuracy
- Logistic Loss
- AUC
- RMSE
- MAE(Mean Absolute Error)
Target Metric是核心。
Platforms
- Kaggle
- DrivenData
- CrowdAnalityx
- Codalab
- DataScienceChallenge.net
- Datascience.net
- Single-Competition sites(like KDD, VizDooM)
Real world ML Pipeline & Kaggle
- Understanding the problem(生成有用的新feature)
- Problem formalization
- Data collecting(external data允许使用时)
- Data Preprocessing
- Modelling
- Way to evalute model in real life
- Way to deploy model
加粗部分为比赛需要注意的部分。
Philosophy of competitions
- 懂数据。算法只是工具,谁都会调包。想要赢还需要更多努力。重点是对数据,问题的理解。有时候甚至用不到机器学习就能搞定一场比赛。
- Target Metric是重点。不要限制自己的手段。Heuristics, Manual data analysis, complex solutions, advanced feature engineering, 复杂耗时的运算,只要对改进模型有帮助都可以大胆尝试。
- Be creative. 尝试改进经典算法来适用于自己的比赛,甚至是自己设计新的算法。不要害怕读并且修改source code。
2. Recap of main ML algorithms
Models
- Linear model
split space into two sub-spaces separated by a hyper plane.
- Tree-based model
split space into boxes and use constant the predictions in every box.
不大适用于区分线性相关的特征
- Scikit-learn
- XGBoost
LightGBM
KNN
based on the assumptions that close objects are likely to have same labels.Heavily relies on how to measure point closeness.
对Distance function的选择:图形处理用square distance是无意义的。不过Scikit-learn中可以选择各种distance function,也可以自定义。
- Neural networks
produce smooth non-linear decision boundary.
Neural Networks Playground: here 很多适合图像,声音,文本,序列学习。
- Tensorflow
- Keras
- MXNet
- PyTorch*(Recommended)
- Lasagne
Exercise
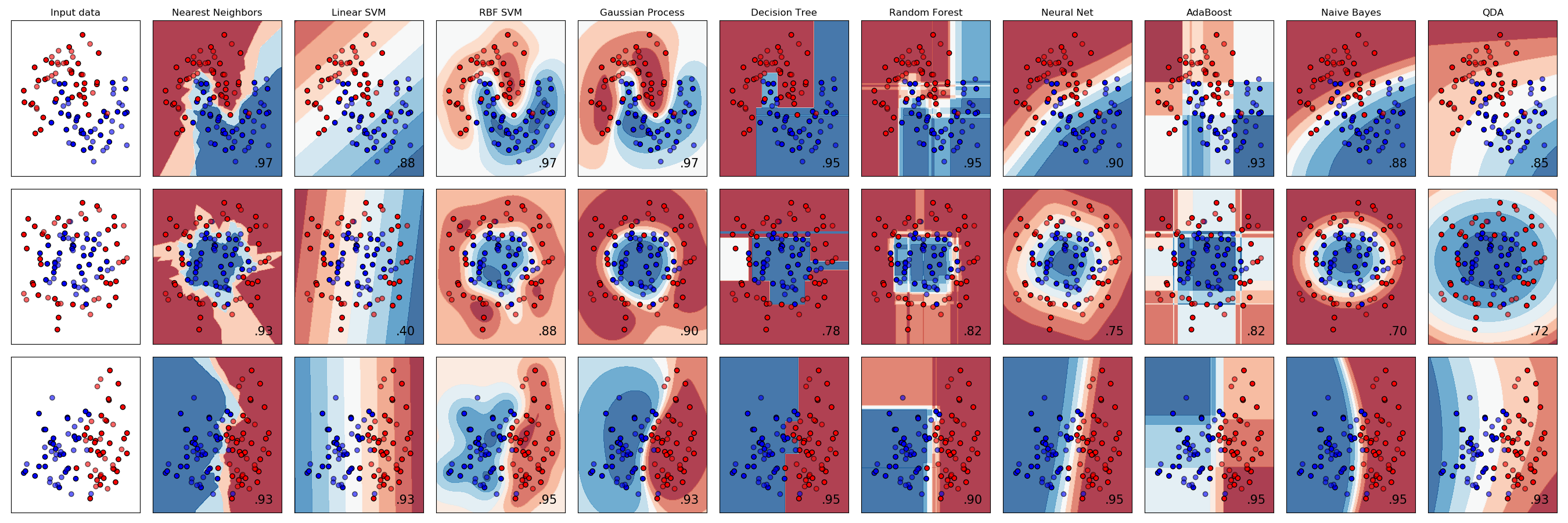
通过学习原理,直观有一个intuition,为何每个模型出现各自的表面结果。
Summarize
The most powerful methods are Gradient Boosted Decision Trees and Neural Networks. But we shouldn’t underestimate Linear Models and k-NN because sometimes, they may be better.
More material
Explanation
- Explanation of Random Forest
- Explanation/Demonstration of Gradient Boosting
Notebook: Will performance of GBDT model drop dramatically if we remove the first tree?
Overview of methods
- Scikit-Learn (or sklearn) library
- Overview of algorithms and parameters in H2O documentation
Additional Tools
- Vowpal Wabbit repository
- XGBoost repository
- LightGBM repository Frameworks for Neural Nets: * Keras,PyTorch,TensorFlow,MXNet, Lasagne
- Example from sklearn with different decision surfaces
- Arbitrary order factorization machines
3. Software/hardware
Hardware
- RAM 64Gigabytes够,128更好(???)
- Cores: 有时候32个都不够(???)
- Storage: 神经网络,图像类问题特别需要ssd
Cloud resources
- Amazon AWS (spot option recommended)
- Microsoft Azure
- Google Cloud
Software
Python rather than R
IDE
Jupyter
Packages
Pandas(effective usage) XGBoost, LightGBM: Gradient-boosted decision trees Keras: neural nets vowpal wabbit: 大数据集 srendle/Libfm, guestwalk/libffm: 各种optimization machines, sparse data baidu/fast_rgf: ensembles, paper
4. Feature preprocessing and generation with respect to models
Features: numeric, categorical, ordinal, datetime, coordinates Missing values
Numeric features
Feature preprocessing
- Scaling tree-based models一般不会受scale的影响,但是non-tree-based models很多都会受影响。想想模型的数学含义,比如KNN。
- to [0,1]:
sklearn.preprocessing.MinMaxScaler - to mean=0,std=1:
sklearn.preprocessing.StandardScaler
- Outliers
- Winsorization:
upperbound, lowerbound = np.percentile(x,[1,99])
y = np.clip(x, upperbound, lowerbound)
- Rank:
scipy.stats.rankdata
神经网络常用的:这些都会把两边的值往平均值靠。想函数凹凸的形状。这都是WorldQuant实习时候用过的伎俩。
1. Log transform: np.log(1+x)
2. Raising to the power < 1 : np.sqrt(x + 2/3)
注意,当模型选Linear models, KNN, Neural Networks时,我们常把不同preprocessing方法得到的数据mix在一起拿去训练,这时候往往效果会更好。
Feature generation
a. Prior knowledge
b. Exploratory data analysis
举例Forest Cover Type dataset,正好是我数据挖掘课设的数据集。 比如数据给了到水源的垂直距离a,水平距离b,应该创建一个直接距离 c = (a^2+b^2)^0.5 。原因显然。 举例,价格的fractional_part,比如2.49的0.49, 9.99的0.99等。可以反应人们对价格的认知偏差。(只要998)又比如判断社交网络的spambot,读取速度如果刚好整数1秒则很可能是,因为人类不可能刚好1秒。 两大关键: Creativity, data understanding
Categorical and Ordinal features
Categorical: 比如titanic数据集的Embarked特征。
Ordinal: order categorical feature. 比如plcass,1,2,3代表几等舱位。显然很有可能直接与死亡率挂钩。Numeric feature的话,数据间的差值是可以评估的,比如1到3和4到6是一样的。而显然ordinal不是,1等舱,2等舱,3等舱之间的差距是否一样是不知道的。
又比如驾照的A,B,C,D,教育的幼儿园,中学,大学,master, doctoral等。
feature preprocessing
- Label encoding
树模型常用
Label encoding(to map it’s unique values to different numbers)。而非树类模型不常用。 - Alphabetical(sorted): sklearn.preprocessing.LabelEncoder
Order of appearance
pandas.factorizefrequency encoding
encoding = titanic.groupby(`embarked`).size()
encoding = encoding/len(titanic)
titanic[`enc`] = titanic.Embarked.map(encoding)
当频率和target value确实有关系时,非树模型则可以捕捉这种关系,比如linear models.
当频率都一样时就无法区分了。后面没听清这个怎么解决。from scipy.stats import rankdata
- one-hot encoding
- If target dependence on the label encoded feature is very non-linear, i.e. values that are close to each other in the label encode feature correspond to target values that aren’t close.
- When the feature have only two(a few) unique values
pandas.get_dummies,sklearn.preprocessing.OneHotEncoder
当然这么干可能出问题,比如某个feature的unique值太多,出来的向量就太多了。这种时候可以考虑sparse matrix。偶尔出现的存1,其他存0,节约内存。
feature generation
- feature interaction
对非树类模型特别是linear model, KNN常用的一招是feature interaction between several categorical features.
如1,2,3等舱和男女,可以得到
X等舱Y性别的特征。
总结
Label/ Frequency encodings常用于树类模型,One-hot encoding常用于非树类模型。但是也不一定(It’s good idea to try both, if you don’t have any better ideas to try)。Interaction可以帮助linear models和KNN.
Datetime
datetime有很多类。
Periodicity: Day number in week, moth, season, minute,自定义(一天半)等….
Time since
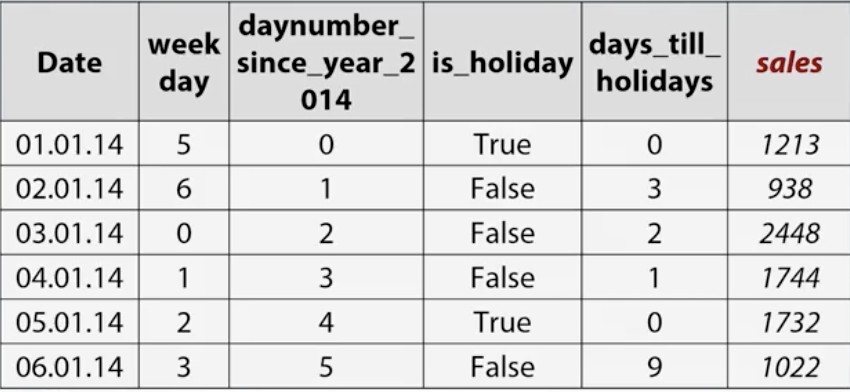
- 独立的:比如自从1970年1月1日00:00:00 UTC
- 相关的: 比如上一个节假日过了几天
- Difference between dates
Coordinate
- interesting places from data(额外数据集)
- Centers of clusters
- Aggregated Statistics
5. Missing values
有时候可以想想missing values为何会出现?
Hidden NaNs
有时候不是NaN的形式出现,会被替换为其他值,比如0到1数据集里出现的-1等。
Fillna approaches
- -999,-1,etc (线性模型,神经网络会跪)
- mean, median(线性模型,神经网络常用,树类模型不好)
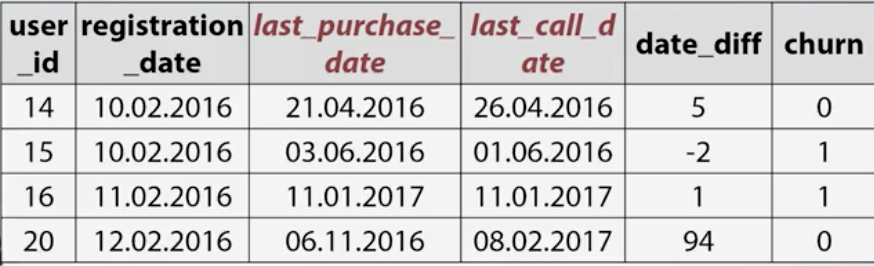
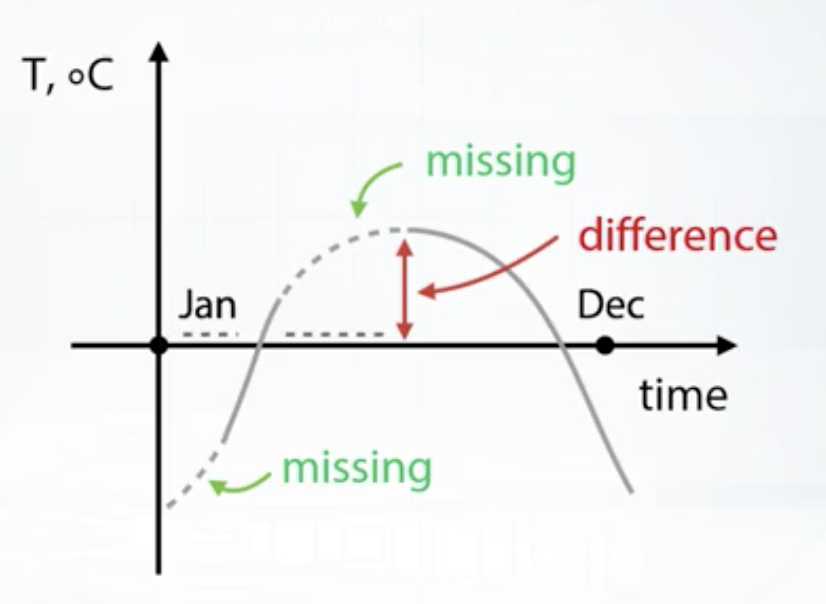
- Reconstruct value 比如时间序列角度,比如分category算统计量等。 fillna要十分小心,median这种东西填进去,如果下图这个例子,difference计算可能会出现异常值。
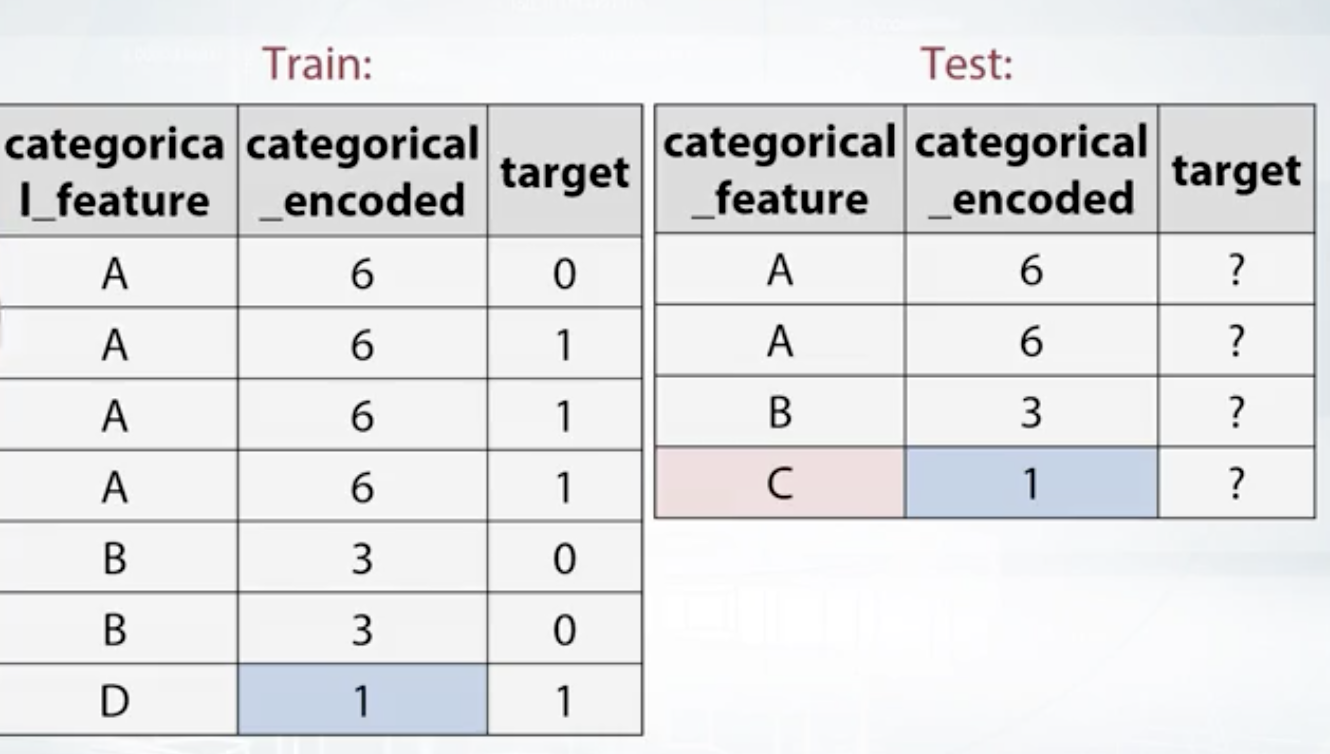
此外,有时test set有某个category而training set没有,某个category is missing, 这时候可以建造一个categorical_encoded,把出现的次数map一下。这时如果出现次数真的表示了category之间的联系,模型就可以捕捉到。见下图。
“Isnull” feature
创建一个binary向量。这个树类模型就可以用了。但是数据的特征量会翻倍。
总结
- choose wisely and consider the actual situations.
- Binary feature “isnull” can be beneficial.
- In general, avoid filling nans before feature generation
- Xgboost can handle NaN Some models like XGBoost and CatBoost can deal with missing values out-of-box. These models have special methods to treat them and a model’s quality can benefit from it.
- Just removing rows with missing values can be an alternative to try.
Links
6. Feature extraction from text/images
Bag of words
Term frequency TF normalizes sum of the row values to 1.
tf = 1/x.sum(axis=1)[:,None] x = x*tfInverse Document Frequency IDF scales features inversely proportionally to a number of word occurrences over documents.
idf = np.log(x.shape[0]/(x>0).sum(0)) x = x*idf
sklearn.feature_extraction.text.TfidfVectorizer
- N-grams:
N-grams can help utilize local context around each word.
N-grams features are typically sparse. Ngrams deal with counts of words occurrences, and not every word can be found in a document.
sklearn.feature_extraction.text.CountVectorizer: Ngram_range, analyzer
Text Preprocessing
- Lowercase
- Lemmatization/ Stemming
- stopwords: NLTK, Natural Language Toolkit library for Python:
sklearn.feature_extracton.text.CountVectorizer: max_df
总结
- Preprocessing
- Ngrams can help go use local context
- postprocessing: TFiDF
Word2vec, CNN
Word2vec
Words: Word2vec, Glove, FastText, etc Sentences: Doc2vec, etc
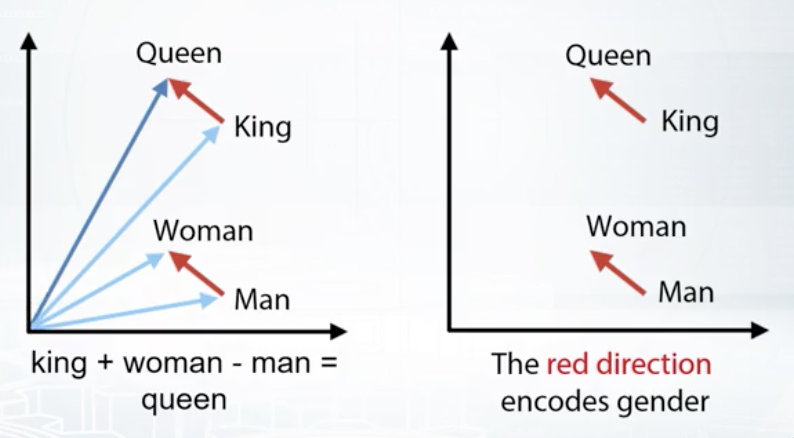
训练Word2vec要花很久,网上有训练好的可以用。比如用wikipedia训练的。 两者对比: 1. Bag of words a. Very large vectors b. Meaning of each value in vector is known
- Word2vec a. Relatively small vectors b. Values in vector can be interpreted only in some cases c. The words with similar meaning often have similar embeddings
两者可以一起用。
Image - > vectors
- Descriptors
- Train network from scratch
- Finetuning (Keras, PyTorch, Caffe…)
Augmentation: 图像有时候可以旋转等方式产生新数据集。比如问房屋的朝向。 Data augmentation can be used at train time to increase the amount of training data and at test time to average predictions for one augmented sample.
总结
- Texts a. Preprocessing i. Lowercase, stemming, lemmarization, stopwords b.Bag of words i. Huge vectors ii. Ngrams can help to use local context iii. TFiDF can be of use as postprocessing c. Word2vec i. Relatively small vectors ii. Pretrained models
- Images a. Features can be extracted from different layers b. Careful choosing of pretrained network can help c. Finetuning allows to refine pretrained models d. Data augmentation can improve the model
Links
Feature extraction from text
Bag of words
Word2vec
- Tutorial to Word2vec
- Tutorial to word2vec usage
- Text Classification With Word2Vec
- Introduction to Word Embedding Models with Word2Vec
NLP Libraries
Feature extraction from images
Pretrained models
Finetuning