D4SG
难得争取到这个机会,好好参加一次,作好学习记录。 http://d4sg.org/events/d4sg-workshop-fcu/ 我们组拿到的题目是这样的: https://hackpad.com/1--wGvRa3bOueF
前置准备
check_then_install("dplyr", "0.4.3")
library(dplyr)
vignette(package = "dplyr")
vignette("introduction", package = "dplyr")
读取数据
違章工廠=有稅籍登記、有(無)公司登記、沒有工廠登記。 为找到并分析违章工厂,需要三部分数据。
稅籍登記
一个洗过的csv表格。乱码。中文,UTF-8Z转BIG5。读取方法如下。
install.packages("data.table")
library("data.table")
result1 <- fread("/Users/shenchen/Desktop/cross_one.csv")
tmp <- apply(result1, 2, function(x) iconv(x, "big5"))
colnames(tmp) <- iconv(colnames(tmp), "big5")
tmp <- data.frame(tmp)
公司登記
这部分是json格式的,计算机专业的组员转成csv,花了一天的时间。json内部的结构十分复杂,如各种董事会等,不对齐,且每一条前面有一些数字,导致无法用正常的工具,函数转换,要手切。
工廠登記
csv表格。乱码。中文,UTF-8Z转BIG5。
#<Windows系統讀取資料,UTF-8轉Big5>
install.packages("data.table")
library(data.table)
dat <- fread("C:/Users/Jason/Desktop/D4SG黑客松/BGMOPEN1.csv", encoding="UTF-8")
colnames(dat) <- iconv(colnames(dat), from = "UTF-8", to="Big5")
head(dat)
我负责处理的表格是税籍登记表,在转码读取后,需要找出制造业(工厂相关)的公司。查询政府文件得到登记编号介于(80000~399999)之间。但是打开表格后发现,表头重复出现很多列“登记编号”,于是换表头以区分。其中“登记编号”为a8,10,12,14。
colnames(dat2) <- c("a1","a2","a3","a4","a5","a6","a7","a8","a9","a10","a11","a12","a13","a14","a15")
筛选处理
之后开始筛选。为什么一列有很多登记编号,是因为一个公司可以有很多项业务,有些属于制造业,有些不属于。那么我们的原则是,只要有一项业务里沾边制造业,就选出。 所以筛选我的思路是,a8,a10,…分别筛选出区间内的,再拼在一起。
#筛选
> a <- filter(dat2,a8 > 80000)
> b <- filter(a,a8 < 349999)
> c <- filter(dat2,a10 > 80000)
> d <- filter(c,a10 < 349999)
> e <- filter(dat2,a12 > 80000)
> f <- filter(e,a12 < 349999)
> g <- filter(dat2,a14 > 80000)
> h <- filter(g,a14 < 349999)
#拼接
for(i in 1:152273) {
for(j in 1:61005 ){
if(d[j,2] == b[i,2]){
x4 <- rbind(x4,d[j])}
}
}
但是这样的代码非常耗时,很久跑不完。逻辑判断运行速度慢,而这里的数据量达到了百万级别。(140万条,最终得到结果只有18万),所以这种方法在这种情况下几乎不可行。 请教教授,优化后的代码如下
#<從稅務資料中篩選出製造業,只要滿足一項行業類別予以就保留>
tmp <- filter(dat2, (a8 > 80000 & a8 < 349999) | (a10 > 80000 & a10 < 349999) | (a12 > 80000 & a12 < 349999) | (a14 > 80000 & a14 < 349999))
head(tmp)
#<輸出csv>
write.table(dat,file="C:\\Users\\Jason\\Desktop\\dat.csv",row.names=T,col.names=NA,sep=",")
至此这张表处理完,交由组员汇总,得到违章工厂。
地理数据
接下来的问题是,需要由得到的工厂的地址(如:新北市五股區五權二路29號(1樓)),回答“有多少違章工廠在農地上?”至此是14日晚的工作。 土地使用分區,也就是农地的资料,两位计算机系组员研究写ython爬虫。我的任务是将地址转化为 经纬度。
查询资料,了解到可以运用Google map api。自定义函数如下
library(httr)
library(RCurl)
library(XML)
library(bitops)
#Import library 容易报错,最好是直接install.packages("RCurl")这样安装
geoPoint = function(address, verbose=FALSE) {
#若未輸入地址, return錯誤
if(verbose) cat(address,"\n")
root = "http://maps.google.com/maps/api/geocode/"
#Google編碼為UTF8, 中文要轉碼後帶入URL才會正確
#address = iconv(address,"big5","utf8") <----------该代码在此情形会出错
#POI API型態(XML or JSON)
return.call = "xml"
sensor = "false"
#產生URL
url_gen = paste(root, return.call, "?address=", address, "&sensor=", sensor, sep = "")
#擷取網頁原始碼
html_code = xmlParse(url_gen)
#若status為OK抓取資料, 若不為OK return status
if(xpathSApply(html_code,"//GeocodeResponse//status",xmlValue)=="OK") {
lat = xpathSApply(html_code,"//result//geometry//location//lat",xmlValue)
lng = xpathSApply(html_code,"//result//geometry//location//lng",xmlValue)
loc_type = xpathSApply(html_code,"//result//geometry//location_type",xmlValue)
return(cbind(lat, lng, loc_type, address))
} else {
return(paste("Status:", xpathSApply(html_code,"//GeocodeResponse//status",xmlValue), sep = " "))
}
}
用此函数处理数据。
position <- select(Data,工廠市鎮鄉村里) #选出只有一列地址的list。
#跑函数,跑一条往下粘一条。
fixpoint <- geoPoint(position[1,]) #for(i in 634:700){
for(i in 2:91035){
fixpoint <-rbind(fixpoint[1:(i-1),],geoPoint(position[i,]))
}
谷歌地图上核对下得到的结果
"新北市新店區寶興路60巷40號1樓"
lat:"24.9716260"
lng:"121.5484570"
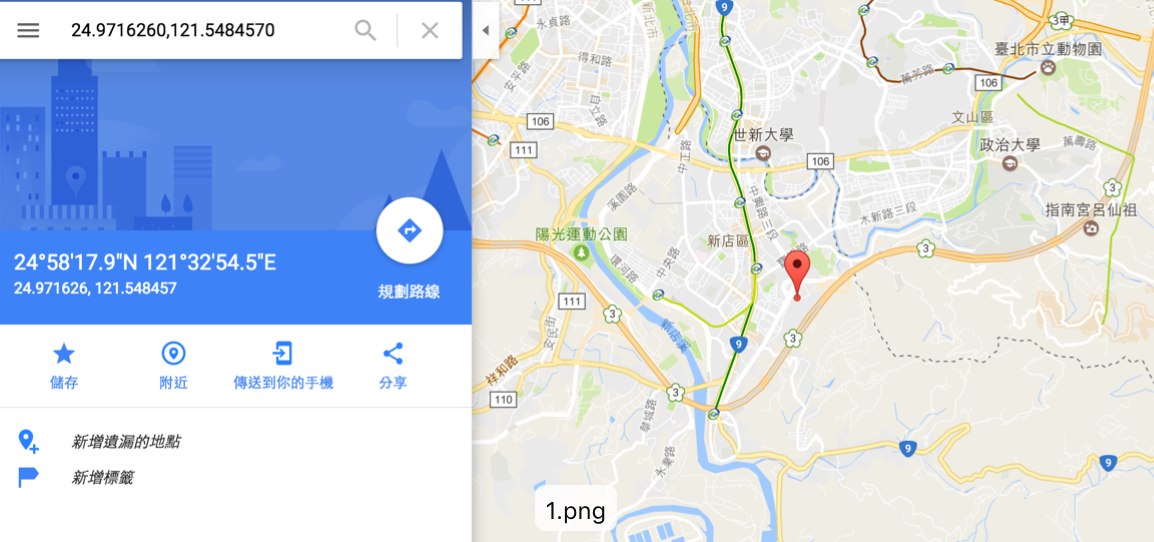 

运行了一会发现这个api似乎运行速度很有限。测试下(调整i in xx:xx),5分钟跑了只有600笔。共91000笔上下,则要跑12小时以上。所以按照之前老师的建议,可能选择处理一部分地区数据,如农田较为密集的彰化地区。 另,老师提到了一款地图软件,QGIS.
筛选出零售业相关厂商。我的代码又出错了,不知道组员之间处理时什么因素让整个表的格式变成了factor,于是重新导出再导入。然后老师给了如下的代码。学习一下这种用(%>%)的排版和思路。
tmpselect12 <- tmpselect1 %>%
mutate(check_a9=ifelse(a9 > 470000 & a9 < 489999,1,0),
check_a11=ifelse(a11 > 470000 & a11 < 489999,1,0),
check_a13=ifelse(a13 > 470000 & a13 < 489999,1,0),
check_a15=ifelse(a15 > 470000 & a15 < 489999,1,0)
) %>%
filter(check_a9==0, check_a11==0, check_a13==0, check_a15==0) %>%
select(-c(check_a9, check_a11, check_a13, check_a15))
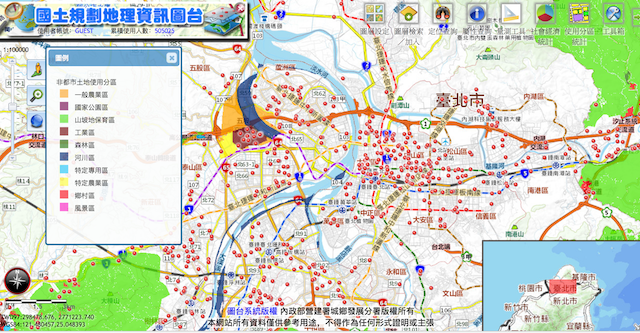
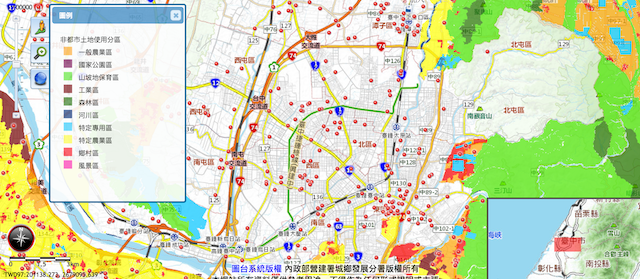
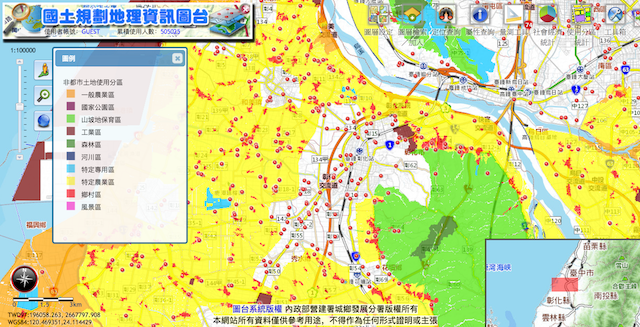
以下是导入到国土局后的结果:来源:国土规划地理资讯图台
台北市
台中市
彰化县,特别。

其余: <資料再剖析及可視化>
1.非法工廠資料再剖析,哪些製造業的資料和農地污染無直接相關是可以捨去的,N個原則可以批量篩選。
2.找出農地的”點”資料(即經緯位置),半徑M公里內有製造業工廠,視為一次試驗成功。
3.可能可以畫:
a.各縣市的違章工廠數量Barchart、Heatplot或散佈圖。
b.各縣市所有工廠內違章工廠的比例,縣市間做比較。
c.相關分析,看違章工廠及汙染是否呈現正相關。