用QQbot+Python背单词
用QQ(其实是Tim)背单词。
为什么要这么折腾呢。因为大环境在这,手上都是些琐碎的时间。坐下来老老实实背三千书和Excel的时间越来越少。其实在大学这几年我一直在思考这个问题,怎么样利用起来零碎的时间。 为什么用QQ: 之前玩微信的聊天机器人时,用过itchat和wxpy。itchat是一个功能很完备的包,Github上star有五千多,但是微信本身其实对多帐号不友好。IOS系统也没有双开帐号的软件。相比下QQ要好很多。 我很惭愧大二一年社团活动下来,养成了手机不离手这个非常不好的习惯,经常动不动就开社交软件看一下,然后十几分钟就没了。所以索性在这些软件里弄点想法。 设想的功能: 三千已经过了一遍了,现在不需要精背,而是需要大量的重复,重复,再重复。就像三千里面那些鸡汤句一样,说的是有道理的。所以我需要的功能有两个,一个是我可以发一个数字,要求我的小号发给我指定哪里的单词;另一个是随机抽取整个三千的单词。均以10个为一次的数量。前者让我可以系统的过单词,后者是满足时不时对自己整体能力的检验。
QQbot: https://github.com/pandolia/qqbot 我在自定义机器人这里构建我自己的代码。
# -*- coding: utf-8 -*-
def onQQMessage(bot, contact, member, content):
elif content == 'Z': #输入'Z',根据手机习惯性大写。随机抽取整个三千中的10个单词。
answerlist=result()
answer=answerlist[0]
bot.SendTo(contact, answer)
...
answerlist=result()
answer=answerlist[0]
bot.SendTo(contact, answer)
elif content == 'offline': #关闭机器人
bot.SendTo(contact, 'offline')
bot.Stop()
else : #输入数字,如20,返回20*10至21*10序号间的10个单词。为一个unit。
for i in range(1,10):
answerlist=fetch(int(content),i)
answer=answerlist[0]
bot.SendTo(contact, answer)
def result():
import random
f = open("/Users/shenchen/desktop/vocab.txt", "r") #文件为vocab.txt
sourceInLines = f.readlines() #按行读出文件内容
f.close()
new = [] #定义一个空列表,用来存储结果
for line in sourceInLines:
temp1 = line.strip('\n')
temp2 = temp1.strip('\t') #去掉每行最后的换行符'\n'
temp3 = temp2.split(',') #以','为标志,将每行分割成列表
new.append(temp3) #将上一步得到的列表添加到new中
result=random.choice(new)
return result;
def fetch(num,count):
import random
f = open("/Users/shenchen/desktop/vocab.txt", "r") #文件为vocab.txt
sourceInLines = f.readlines() #按行读出文件内容
f.close()
new = [] #定义一个空列表,用来存储结果
for line in sourceInLines:
temp1 = line.strip('\n')
temp2 = temp1.strip('\t') #去掉每行最后的换行符'\n','\t'
temp3 = temp2.split(',') #以','为标志,将每行分割成列表
new.append(temp3) #将上一步得到的列表添加到new中
result=new[num*10+count-1]
return result;
将三千Excel做成txt的时候遇到了换行的问题。Excel里面的中文词义解释有时存在单元格内的换行,粘到Sublime里面自己变成了一行,这样一个单词一行的格式就破坏了。 解决办法: 将Excel的表格复制到Word中,查找替换”^l”为空,然后粘回Excel,再粘到Sublime就可以了。 效果如下:
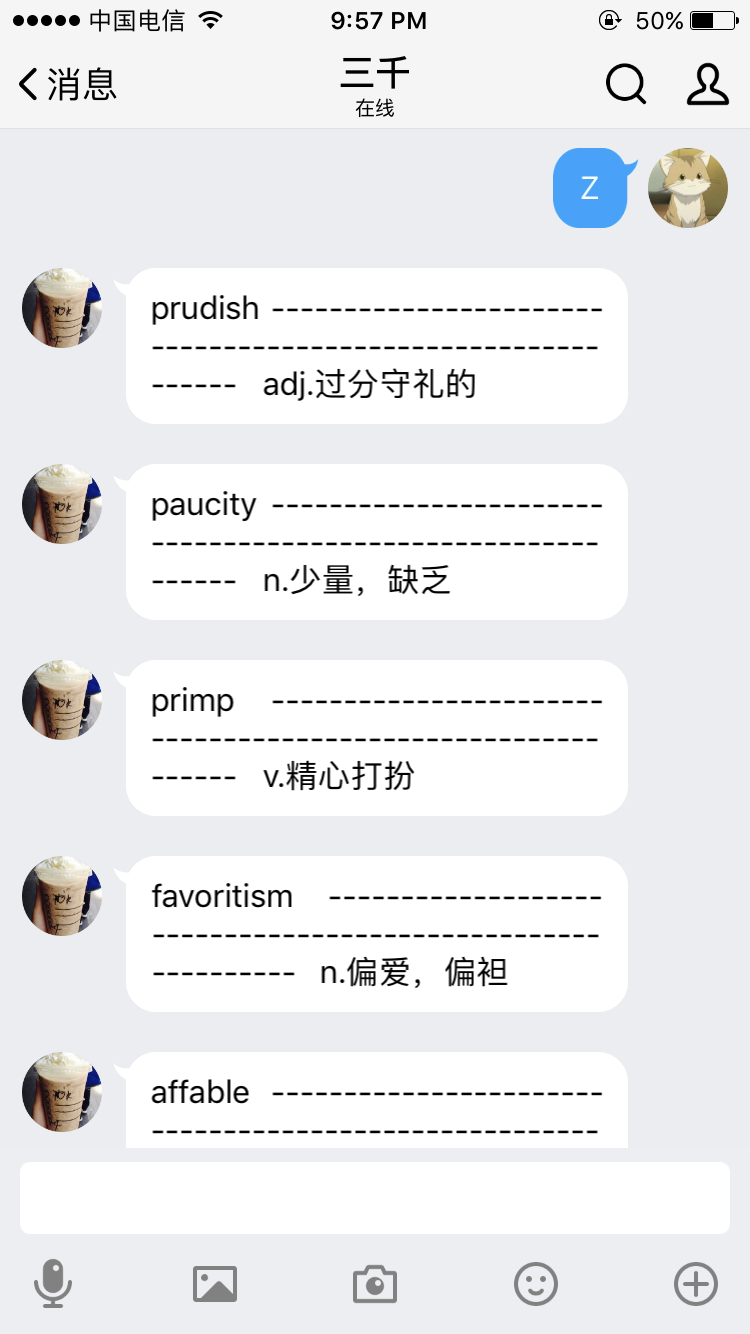
下午去万达见老同学,地铁上背了一个小时,还是蛮爽的。配合手机上的词根词缀字典巩固那些比较抽象的单词。 今天才发现这个app。40岁大叔带来的感动。感觉相见恨晚,功能简直完美,我所有想要的基本都有了。明年要是有了好去处一定记着饮水思源一下。